


The skinny: We fixed missed-schedule posts by reducing the site’s code landscape, examining the hosting environment, and implemented a three-prong, bulletproof approach to ensuring posts publish on time. In the process we also trimmed megabytes of render-blocking CSS and JavaScript, changing the site’s performance measured by Google Lighthouse from 17 to 75. So, that’s nice.
But first
A primer: We generally build WordPress sites that we ourselves have designed, and as part of that we build from scratch. This ensures we know every part of the site is high performance and security solid.
But we also inherit sites built before us. Often a site is handed our way because there are frustrations or limitations with the prior developers. Either of those scenarios generally mean we’re inheriting a site with code bloat, and by extension technical-debt.
Inheriting (or creating) code bloat means troubleshooting will be more difficult, and this was particularly true with one major site we maintain. They have an editorial schedule that requires scheduling posts within WordPress, and far too often they would log in to WordPress to see the post didn’t go out at the scheduled time and would be labeled “missed schedule”.
Having built multiple enterprise, battle-tested healthcare apps in the last few years, we’re generally able to detect and fix problems. But troubleshooting this WordPress ecosystem always presented a big challenge and we were indeed short on definitive answers, which (to state the obvious) is demoralizing to not be able to provide real, actionable answers to a client. In addition, there were sporadic but significant remarks about the site working slowly, which was also hard to pin down. So to help in solving both efforts, we first aimed to trim bloat.
Ok, but what the heck is the missed-schedule issue in WordPress?
It’s complicated. Ideally, you’d schedule your post to go out at 8 am Wednesday on some date, and yet you log into WordPress later to find the label “missed schedule” next to your scheduled post. And even though WordPress knows it’s past schedule, it’s still sitting there. Not published. WTH.
To understand how it works, you have to glimpse the mechanics behind the scenes. Put quickly, despite WordPress being a hugely-sophisticated piece of machinery, it’s ultimately only web software that sits atop a server, and it doesn’t have direct access to what servers call a “cron job” (short for “chronological” or “time-based” job). A cron job is just a scheduled task. I can instruct the server to “do this thing every hour of every day“, and it’ll do it. It’s really powerful.
But WordPress doesn’t have server access that deep. So it relies on a pseudo-cron job that isn’t chronologically-based, but “event-based”. What’s the “event”? Someone visits the site. That’s it.
The Big Event
When someone visits the site, that counts as an “event”, and WordPress will be triggered to run through its routines, including performing any scheduled tasks. But…let’s say you scheduled your post at 8 am Wednesday, and your site is low-traffic enough that you didn’t get a visitor until, say, 9 am. Well, WordPress ran through its tasks at 9 am and determined that based on the current time, your post is now behind schedule and labeled as “missed-schedule” instead of deployed. It’s a frustrating and kind of stupid feature.
But missed-schedule isn’t just an issue that plagues low-traffic sites. High-traffic sites are troubled as well, just different mechanics. This part of things gets much more nuanced because higher-traffic sites will inherently have more complicated server setups, plugin ecosystems, and other dependencies that can affect server routines.
To explain the problem we were solving more directly, which was a high-traffic site on an enterprise-level hosting plan with a major Managed-WordPress provider, we need to talk about all these other ecosystem dependencies.
So is this the reason for the refactor?
It is, and that’s an astute observation, so I thank you for that. The site we inherited was based on the parent-child theme pattern in WordPress, which in many cases can mean a lot of extra boilerplate code your client’s business doesn’t need and also which is hurting their SEO. So, to combat that tech-debt, we opted to rid the reliance on a parent theme.
To be sure, the exercise for refactoring wasn’t academic. There are real-world benefits to trimming any codebase, especially if it affects the code shipped to a browser. Reduce code shipped to a browser and you’ll ostensibly impact SEO in a positive way (with limits, of course. I mean, if your UX is terrible, shipping less code isn’t your problem).
Refactoring was difficult. For one, the parent theme had a ton of boilerplate CSS and JavaScript, some of which we needed (barely), so we had to extricate it. This is not easy nor fun. Said best by one of the gurus of CSS about trimming extraneous CSS:
Here’s what I’d like you to know upfront: this is a hard problem.
Chris Coyier
It was indeed hard. We painstakingly separated the child theme from the parent, bringing over only the parts we needed. Once that was done, we then tackled the plugin ecosystem to rid WordPress of plugins that added little value (or which were determined to be no longer needed because of business rule changes). With that done, it helped us reduce complexity so as to troubleshoot more efficiently.
But at this point, we’d only trimmed enough to be able to solve the missed-schedule posts issue. The site was still bloated and things like page-load time (and UX and SEO by extension) were still going to suffer if we didn’t remedy the frontend bloat that slows loading and hinders good UX.
Hang on a sec: it’s worth noting that we never sought to delay this cleanup effort, nor was our client unwilling to condone this effort. Good businesses are busy. We did what a lot of developer groups do, which is to deal with what you have, make it work, and where possible, fine-tune it and make it better as you go. In this case, we were able to go an extra few steps thanks to a less-demanding sprint.
So we examined the CSS and JavaScript dependencies that had been historically loaded into the existing site. This is because CSS and JavaScript are render-blockers. Normally a page downloads all the HTML it needs (including images, JavaScript, and CSS files) and then parses all the CSS and JavaScript to determine how they will impact how the page looks or feels.
If you have just enough CSS to style the page, parsing will be fast and the user will see the page quickly. Same with JavaScript. Quick parsing means the end-user sees your content quickly. But if you’re dealing with any of the zillions of clock-punching, cavalier web devs out there, it’s common to find they’ve installed 45 WordPress plugins, and in addition, they’re using a ton of extra CSS and JavaScript libraries where maybe 1% of it is needed. They build the site, get paid, and then it’s on to the next disaster someone else will have to clean up.
In examining the leftover CSS and JavaScript, we found terrible, terrible things.

Warning: if you already understand best UX/dev practices, what you’re about to read may be horrifying. Viewer discretion is advised.
Things like boilerplate.css version.whocares were loaded (hundreds of KB in CSS!), despite in Chrome Devtools you could see the coverage was less than 0.5%. It was needless, page-load-hurting waste. And JavaScript payloads were also huge, which is unarguably the most expensive payload you can ship to a browser. Developers for enterprise-level clients can’t just write/include code that “gets it done”. It has to be necessary and purposeful. Including a bloated-boilerplate CSS file, where 99%+ is unused, is negligent for the singular reason that building websites requires thinking about the end-user’s experience.
We managed to make some huge reductions in critical JavaScript and CSS, and the impact wasn’t small. We saw page-load times go from 5-8 seconds to more reasonable 1-2 second loads. Here’s a snapshot of before and after for the most expensive resources a browser has to deal with:
Before
- JavaScript => 2.4MB across 35 files (15 in the <head>)
- CSS => 866KB across 19 files (14 in the <head>)
- WordPress Plugins => 29
- Image loading protocol => load everything all day! Woohoo! {wild west gun shots in the air}
After
- JavaScript => 54.4KB across 3 files (1 in the <head>)
- CSS => 200KB across 3 files (1 in the <head>)
- WordPress Plugins => 15
- Image loading protocol => if an image is below the fold, load asynchronously to avoid impacting initial render
That’s an enormous reduction in JavaScript, particularly in the <head> section. Same with CSS. Though the total reduction in CSS still isn’t where we want it to be, it’s a dramatic improvement readily viewable by clicking around the site.
In particular, reducing the number of files in <head> was key. If it’s in the <head>, the browser will try to parse it immediately because it assumes the CSS is necessary to render the page. This delays rendering any kind of content, so the user sees a white screen.
Cue the hipsters crying “just use a static site generator!”
Yes, static site generators are all the rage right now, but they don’t magically solve the problem of a bloated site, let alone a WordPress site. If you connect WordPress to a static site generator without doing the hard work of a refactor to trim bloat, those flattened output files are still going to have all the bloated CSS/JS, which will require the same long list of network requests as well as browser-parsing time needed to display the page. Mission, not accomplished.
Let’s just throw more hardware at the problem!
— irresponsible web developer
To protect the innocent, I’ll say this client’s large WordPress site is already hosted on a high-performance, managed-WordPress hosting platform that’s served via Nginx and also backed by Redis, and the hosting plan, in particular, is enterprise-level with plenty of resources.
Hardware wasn’t the issue. Shipping enormous, wasteful, parse-intensive payloads to the browser was the issue. We chiselled away at bloat where we could, but lest our client get increasingly frustrated with site slowness and posts not publishing on time, we needed to go all in.
What about the missed-schedule issue?
Right, back to that. After trimming the site’s fat, we moved toward troubleshooting.
As I said, high-traffic sites face the missed-schedule issue as well. With our client’s site, we felt that by reducing the plugin ecosystem would narrow down errors. In examining the many cron-tasks within WordPress, it appeared some of them were hogging resources, possibly causing server timeouts that didn’t allow other cron tasks to execute (like the “publish future posts” task needed for editorial schedules).
While reducing plugin bloat helped, we still saw the issue, and it owed partly to the problems from the hosting provider — namely, caching.
This enterprise-grade, Managed Hosting provider did the flat-file caching for us (just like a static site generator does). This is great to keep performance high, but this effectively means your server-side PHP is no longer working to serve up your site, but instead a pre-flattened HTML page is served.
Without a server request triggering the necessary PHP routines for WordPress to detect the “event” of a site visitor, PHP-triggered cron-jobs wouldn’t know when to run. So you’re damned if your site is low-traffic, and damned when it’s too high.
A three-pronged fix
1.) Since the content managers are actively in WordPress every day, we banked on the fact that caching is disabled if you’re logged into WordPress. This means any PHP you write will actually run. So we added code to functions.php to detect posts that need to deploy when scheduled (as well as those “missed schedule” posts that are behind schedule).
Here’s what we added to functions.php. This fires when a WordPress-admin user hits the Posts or Pages tables, something we know happens often and therefore was a good place to trigger this, below. (Note: for the security-minded folks, yes, we’re not using a prepare statement for our MySQL. But our method accepts no inputs and therefore runs exactly as we expect, negating the need for sanitizing or preparing statements.)
function check_posts(){
global $wpdb;
$date = new DateTime("now", new DateTimeZone('America/Los_Angeles') );
$now = $date->format('Y-m-d H:i:00');
$sql="SELECT ID
FROM $wpdb->posts
WHERE post_type IN ('post', 'page', 'other_custom_posts_types_here')
AND post_status = 'future'
AND post_date < '$now'
";
$results = $wpdb->get_results($sql);
if($results) {
foreach( $results as $p ) {
wp_publish_post($p->ID);
}
}
}
add_action( 'load-edit.php', 'check_posts');
2.) But what about times when we don’t expect a user in WordPress (like crack o’ dawn publish times)? For these cases, we’d have to not rely on PHP since the hosting provider does such aggressive caching. So we used JavaScript to trigger the server to run our PHP.
Using just a bit of JS, we could hit our own bespoke endpoint, which would then run our routine just like above. For that, we dropped in a simple jQuery AJAX snippet into our footer, so that it’d run on every page. Example:
$.ajax({
type: 'POST',
url: '/wp-admin/admin-ajax.php',
data: {
action: 'check_posts'
}
});
So at this point, anyone clicking around WordPress will help trigger the cron-tasks, and anyone visiting the site’s frontend will also trigger it. But…what about when it’s 5am and no one is really visiting the site and no one is in WordPress? Here, we rely on an actual cron-job. Since the current managed-WordPress hosting provider the client uses doesn’t allow us to set cron-jobs (because it’s “managed” hosting and server access is limited), we looked elsewhere.
3.) On a separate server we manage, we set up a simple task (a true cron-job) that would hit a URL (our custom API endpoint) that would trigger code just like above. We set this to trigger the cron-job every 5 mins. So in the rarer likelihood that our first two approaches missed deploying a scheduled post, our bonafide cron-task would swoop in.
So we now have three different prongs tackling the seemingly intractable problem of having scheduled posts go out reliably within a heavily cached hosting environment. Even in the dead of night, our every-five-minutes cron task hitting our custom endpoint will trigger the proper release of scheduled posts.
Important: if you arrived here looking for a fix for missed-schedule, you will want to employ all three of these approaches so that it’s as bulletproof as possible. If you don’t have access to a server to setup your own cron-job, there are external services you can use.
Examples (note: I have not used below but they are popular solutions):
The results are awesome
In the end, we solved the missed-schedule issue and also sped up site performance by a huge margin. Besides the stats above where we reduced payload and sped up the time to load a page, we also achieved higher scores with Google’s Lighthouse tests.
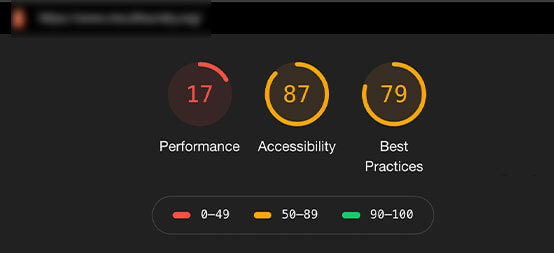
Here’s a look before we deployed the refactor:
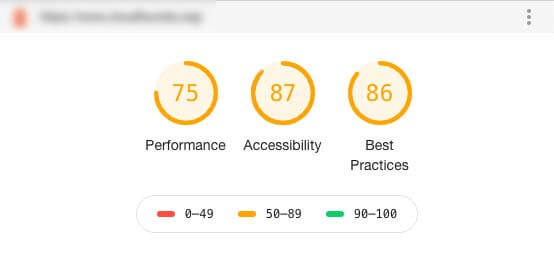
And after:
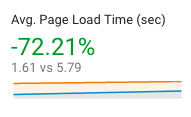
In addition, the initial impact reported through Google Analytics shows a -73% change in average page load time (5.79 secs on average reduced to 1.61 seconds!)
It’s a challenge whenever attempting to refactor code, let alone an entire site. One may wonder whether redoing the entire site would have been better. The answer is always yes, but budget constraints have to be taken into account given other business priorities for the site.
In the coming weeks and months we’ll be in a position to evaluate how the SEO was impacted, and we suspect it’ll result in favorable gains.
Credit where it’s due: hero photo by Markus Spiske
No comments yet. You should be kind and add one!